On-boarding to Apache Kafka: Part Two
Introduction
In the part one of this series we talked about our discovery journey to identify and on board to a versatile pub/sub platform. In this one, we will cover details of our first use case for Apache Kafka
Our First Use Case
Justworks business is powered by Ruby on Rails application built in-house. Like any business critical application, we generate and collect event logs for each and every important business step being executed on the platform. It is upto developers and product discretion what event logs they want to generate which can be used for after-the-fact business analytics, audit or troubleshooting purposes. Unlike, application logs these event logs are semi-structured (i.e. JSON format but no strong schema checks) and are loaded to AWS Redshift database.
Redshift act as our all purpose OLAP store. While we have an existing pipeline built using logstash and Redis to ship these event logs to Redshift, it is fraught with some serious cons. First and foremost, it has the “single point of failure” and second, is huge lag between the time an event is generated and the time it shows up on Redshift.
Hence, we decided to re-engineer our event logs data pipeline by leveraging Apache Kafka.
High level Design for existing data pipeline
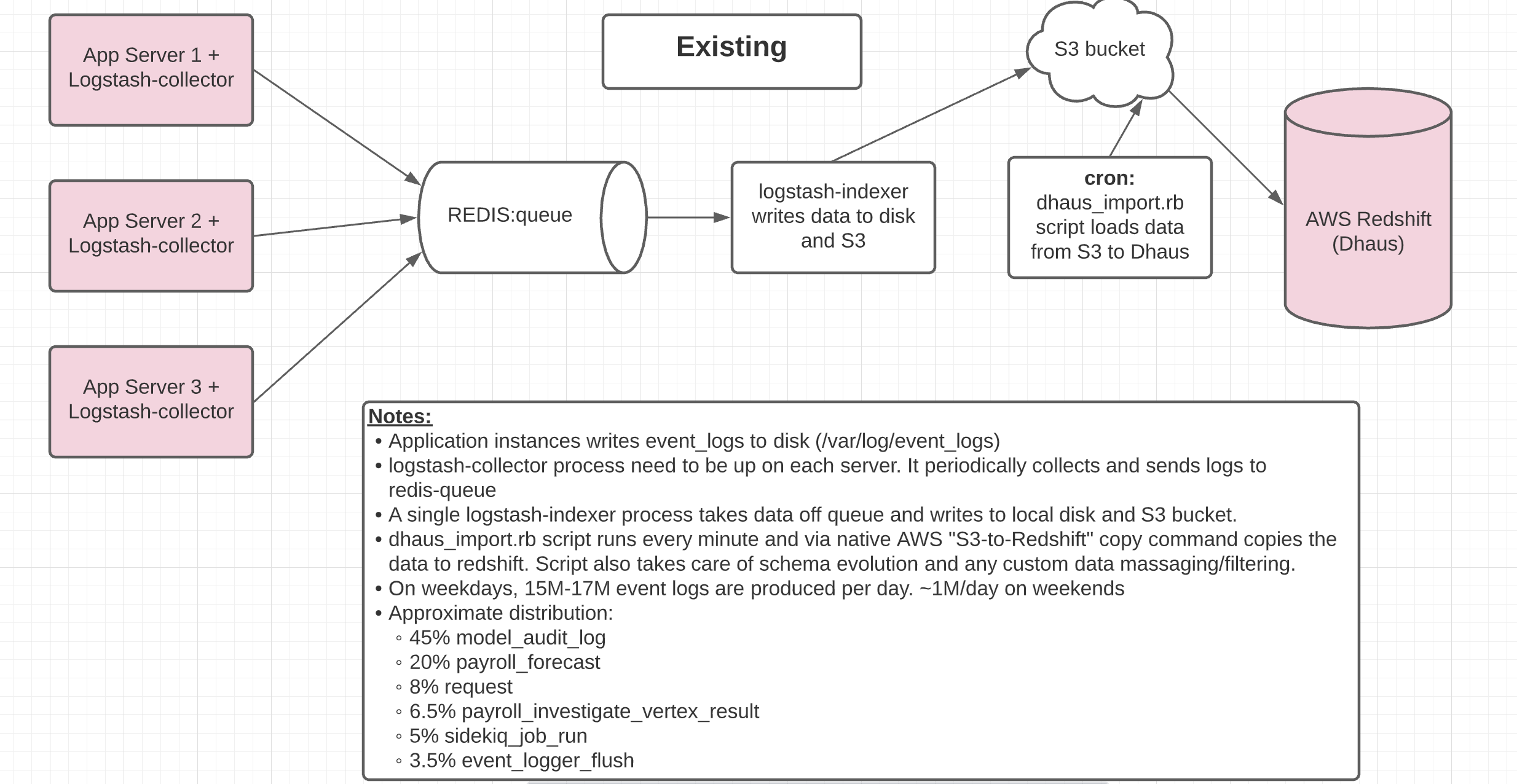
For more details on the existing data pipeline click here.
High level Design for new data pipeline
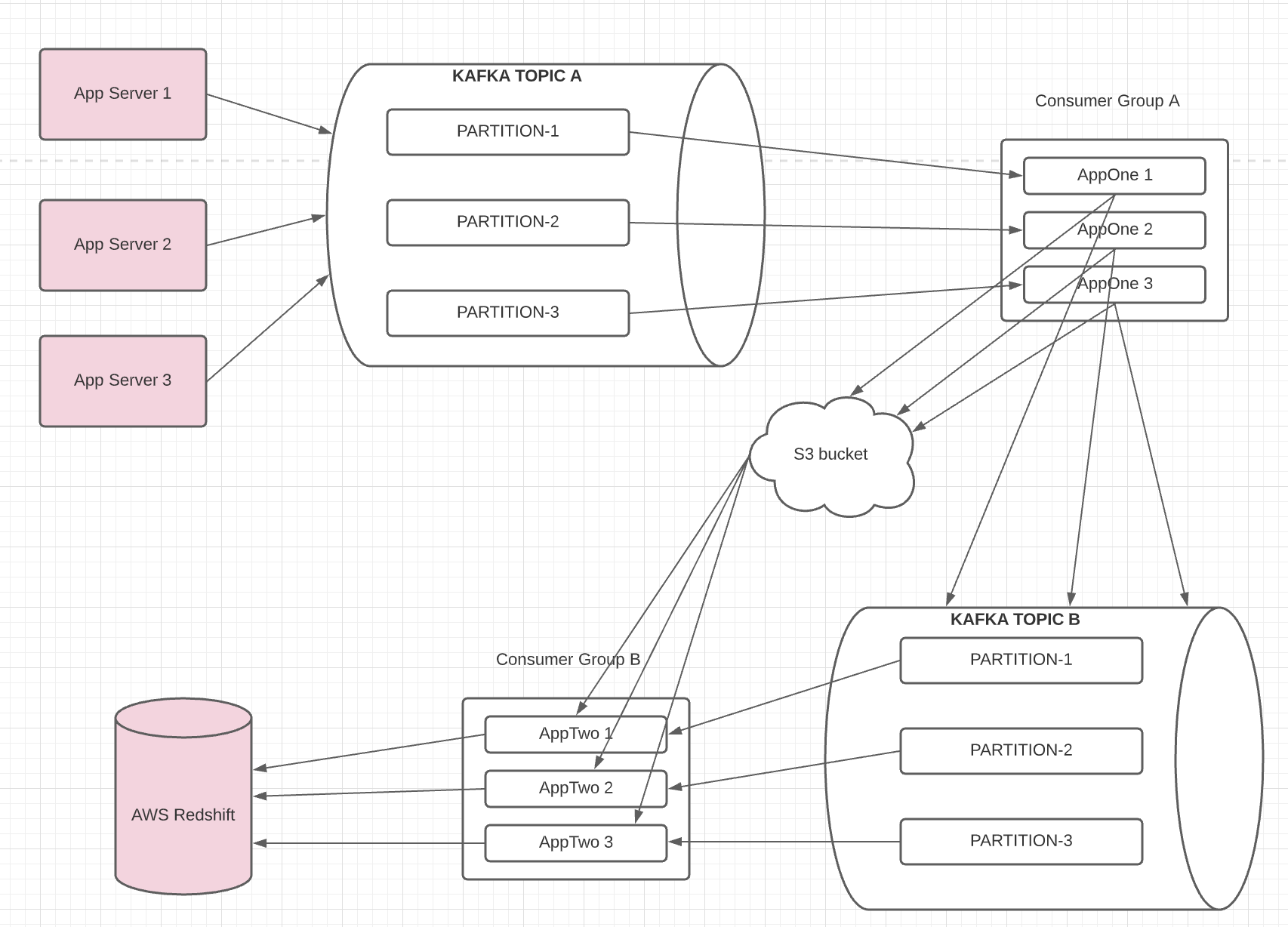
Summary of the data flow via new pipeline:
- Business application instances (i.e. rails servers as well as sidekiq servers) publish event logs to Kafka topic A
- The first application consumes these event log messages from topic A and group them by event key before shipping them to S3 bucket.
- After that it publishes a metadata message to a downstream topic B. This message is light weight, and ony carries information about S3 file(s) which have event logs.
- The second consumer application will consume the metadata message and takes care of loading data from S3 to AWS redshift via AWS native copy command.
- For better throughput, resiliency and scalability, both Kafka topic A and B have multiple partitions (N).
- And both the consumer applications have N instances.
- The existing business logic (e.g. filtering out or masking sensitive data) remains unchanged.
Old and New data pipelines in parallel
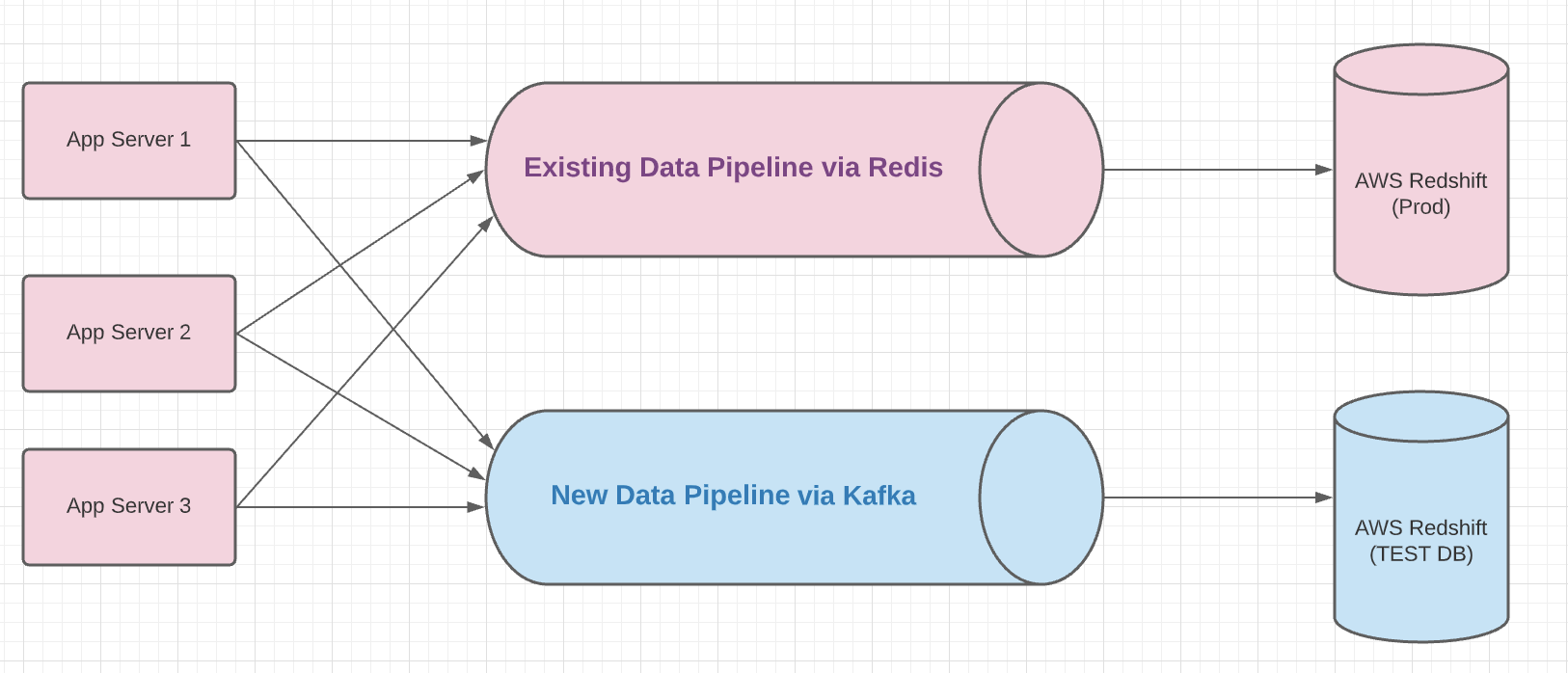
Often when we re-engineer an existing system the first and foremost acceptance criteria is: “New system should produce same output as an old one”. From Business Intelligence team’s perspective, if the new system leads to data loss or bad data then it is a no go. Hence, to derive confidence in the new system we decided to run both old and new pipeline in parallel. This allowed stakeholders to perform data re-conciliation as well as do latency and throughput comparisons.
To be continued…
In the subsequent posts of this series we will do deep dive on kafka libraries and frameworks we are working with. In addition to this we will cover DevOps around CI/CD and containerization of our consumer applications.
Stay tuned!!!